Building GPT from Scratch - Part 4: Further Optimizations
Aug 7, 2025
This is Part 4 of our GPT from scratch series. Having built a complete transformer in Parts 1-3, we now look at further optimizations for more efficient training.
Restructuring and Configuration
Now that we have successfully implemented a transformer network, we can make a number of adjustments to optimize for more efficient training.
First, we restructure our script and put all hyperparameters into a config class:
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'using device: {DEVICE}')
config = Config(
batch_size = 64,
block_size = 64,
max_iters = 5000,
eval_interval = 500,
learning_rate = 3e-4,
eval_iters = 10,
n_embd = 128,
n_head = 4,
n_layer = 6,
dropout = 0.2,
vocab_size = vocab_size,
)
model = GPTLanguageModel(config, device=DEVICE)
model.to(DEVICE)
model = torch.compile(model) # requires PyTorch 2.0
As you can see, we also compile the model before training to improve training speed.
Efficient Multi-Head Attention
The next big change we make is to compute the keys, queries, and values for the multiple heads all in a single matrix multiplication. This means we combine the 'Head' and 'Multi-Head' classes into one single class, which processes the heads as a new batch dimension.
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, config):
super().__init__()
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# key, query, value projections for all heads, but in a batch
self.attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=False)
self.proj = nn.Linear(config.n_embd, config.n_embd, bias=False)
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.register_buffer("bias",
torch.tril(torch.ones(1, 1, config.block_size, config.block_size)))
def forward(self, x):
B, T, C = x.size()
q, k, v = self.attn(x).split(self.n_embd, dim=2)
# reshape and move head dimension forward using einops
k = rearrange(k, 'b t (nh hs) -> b nh t hs', nh=self.n_head)
q = rearrange(q, 'b t (nh hs) -> b nh t hs', nh=self.n_head)
v = rearrange(v, 'b t (nh hs) -> b nh t hs', nh=self.n_head)
att = (q @ k.transpose(-2, -1)) * k.size(-1)**-0.5
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
# re-assemble all head outputs side by side
y = rearrange(y, 'b nh t hs -> b t (nh hs)')
y = self.resid_dropout(self.proj(y))
return y
Flash Attention
Finally, we implement flash attention, which reorders the attention computation such that computations can be tiled which greatly speeds up the attention step.
# In MultiHeadAttention class
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
# ... in forward pass ...
y = torch.nn.functional.scaled_dot_product_attention(q, k, v,
attn_mask=None,
dropout_p=dropout_p,
is_causal=True)
Training Performance and Scaling
Training on a T4 GPU, a 1.2M parameters model now trains in 2 minutes. We are ready to scale up to the size shown in the tutorial video:
config = Config(
batch_size = 64,
block_size = 256,
max_iters = 5000,
eval_interval = 500,
learning_rate = 3e-4,
eval_iters = 10,
n_embd = 384,
n_head = 6,
n_layer = 6,
dropout = 0.2,
vocab_size = vocab_size,
)
This has 10 million parameters and trains in 30 minutes! Let's take a look at the output:
BRAKENBURY:
Despite of this seven sit in the noble
Of Lord Hastings, and my grave is my charged mine;
For George shall not speak not pass'd it:
The valour upon it. Is deliver'd it with me?
BRUTUS:
Yea, beggar, by your voices and hearts,
But since she changed in your packs and bloody,
Your joy your might in him writ
Be punk'd between pains. I am struckcomment
To son I writ you that yet you did love:
If it were example to your knees to express
By your fleships of state? Exeter, me
And wring, my son, come on, my sorrow ladys,
Whose profession joy wings and me down,
Pretty good! Most words are recognizable and the sentences have more structure. The overall form is also consistent with the training data with readable names (Brutus is a familiar one!)
Bias-Variance Trade-off
If we plot the losses against training steps for our small 0.3M model and our final 10M model:
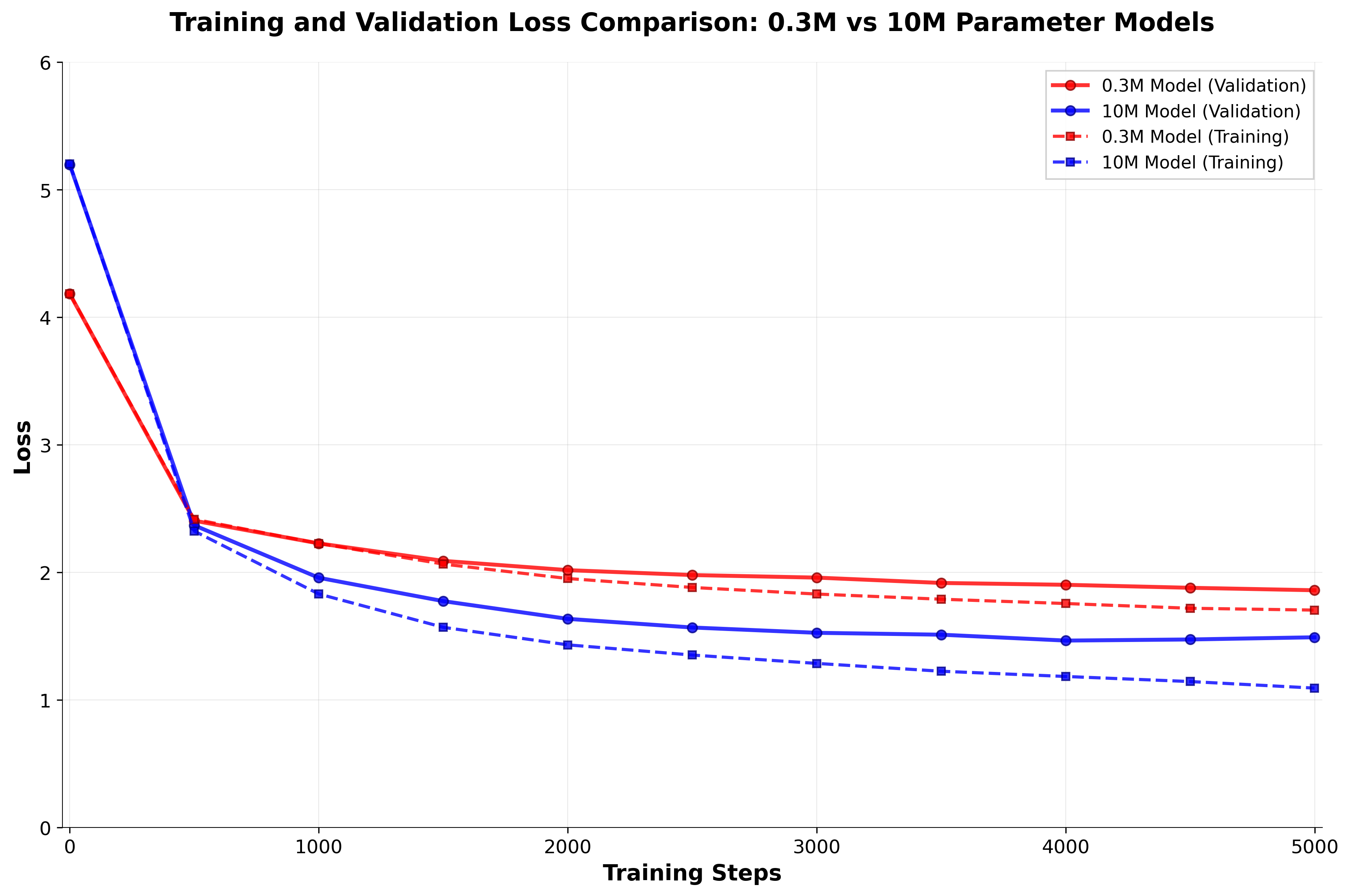 The larger model generalizes better (has a lower validation loss) but overfits more (training loss is much lower than validation loss). This represents a classic bias-variance trade-off in neural scaling. The larger model's increased parameter capacity enables better feature representation learning and pattern recognition, resulting in lower validation error. However, this same capacity creates memorization potential for training data.
The larger model generalizes better (has a lower validation loss) but overfits more (training loss is much lower than validation loss). This represents a classic bias-variance trade-off in neural scaling. The larger model's increased parameter capacity enables better feature representation learning and pattern recognition, resulting in lower validation error. However, this same capacity creates memorization potential for training data.
Conclusion
These optimizations demonstrate how production transformer implementations differ from educational versions. The key improvements - configuration management, batched attention computation, model compilation, and flash attention - provide significant training speedups while maintaining the same underlying architecture.
The scaling results show that our simple transformer can achieve reasonable quality when given sufficient parameters and training time, following the same principles that power modern large language models.